RStudio to Ulysses to Ghost

In much of my work, I use the R statistical programming language and the RStudio IDE to create quantitative aspects of my content. R is a great platform, and the lingua Franca is used for collaborative analyses in biological and ecological studies. It is also an excellent platform for creating teaching content and integrates with Pandoc and Quarto. This is the result for scientific writing, as I commonly push to PDF and go from there.
However, I have a detailed format for the output for writing that goes online or as a component of a more considerable teaching effort. I love Markdown and RStudio, but they are not meant to be primary writing mediums and lack many elements that make writing more of a pleasure than just banging out ASCII in Vim. For this, I use Ulysses.
So, the motivation here is to document and provide examples of the tools I’ve put together to make the following workflow easier. I’m adding the last component here—export to Ghost—as Ulysses has perhaps the best integration with Ghost I’ve seen so far, and I keep most of this content on that system.
Configuring Quarto Documents
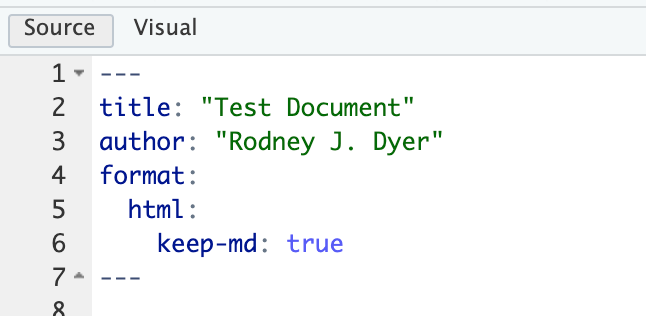
First, I set up my projects with either a _quarto.yml settings file to cover all the markdown documents, or you can put the same content into the header YML metadata in each document you want to use. If you have a mix of content that will be published through Quarto (say hosted by GitHub), then a per-document format may be easier because it keeps around a lot of extraneous information that you do not need to add to your git repository (you are using git to keep all your project organized, right?).
Here, I specify that when Quarto renders a document to HTML, it should retain the intermediate markdown file (keep-md: true). The retained content will be kept in the exact location as the original \*.qmd file.
If the output is not being published directly (say via GitHub), I keep the content in the markdown document to a minimum, mostly just raw sectioning, notes to myself about assumptions and methods (very brief), and leave all the verbiage creation for later.
Here are the main stumbling blocks I’ve found and how I’ve minimized their impacts on the overall workflow.
Tabular Output
If you use kable() for your table creation, it will, by default, put the tables into a code chunk of type html. This is great if you were going directly to HTML, but since we keep the intermediate stuff, I like to keep it as Markdown. To do this, you’ll need to indicate to Quarto that you do not want to be very fancy on the table output and have it rendered #| results: as is.
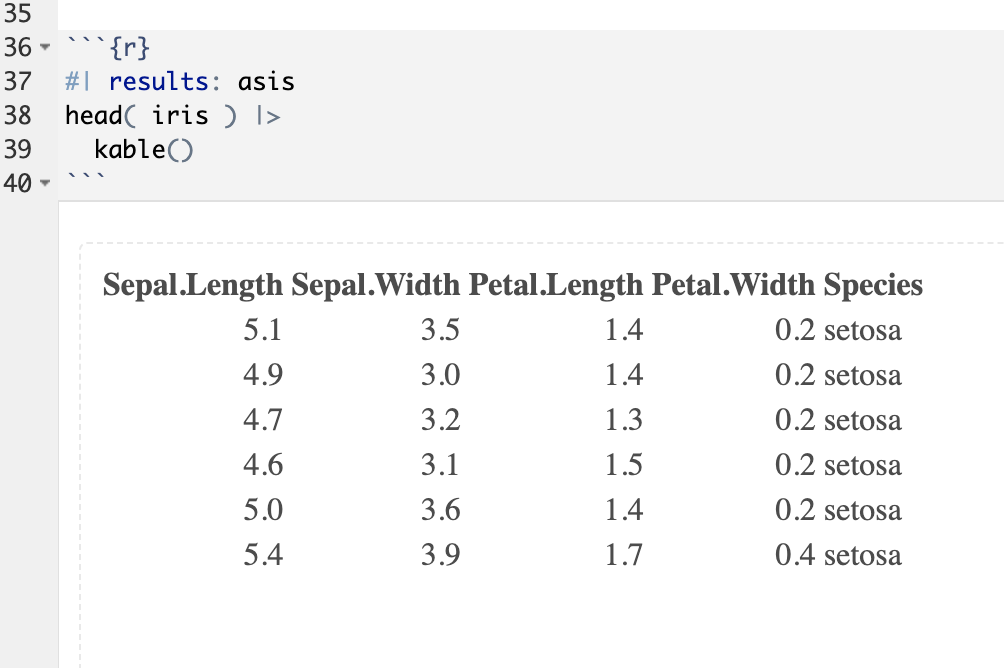
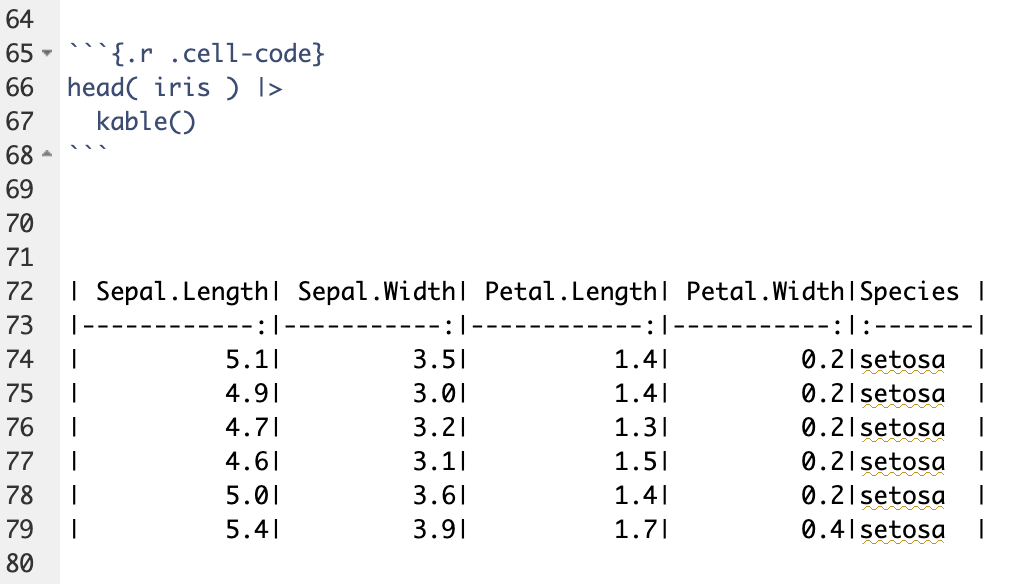
This will still look fine in the rendering, as well as in the HTML output for previewing, but it will make it into a markdown tabular format in the document that looks like this (which is read directly by Ulysses):
If you want the fancy table features that come with kableExtras(), you’ll have to look elsewhere.
Dealing With Figures
Quarto creates images from either your code or Markdown. When you keep the intermediate components of your work as markdown, it makes a folder following your document (and with the same name) and puts them inside there. It puts them in a subfolder named figure-html and then orders them by name. If you get in the habit of naming the chunks that make figure output, it will mimic those names in the images it creates (the example here is from a chunk named plumDensityPlot).

Cleaning Up Rendered Content
The markdown format that Ulysses uses (by default) is MarkdownXL, and Quarto uses a few odd things to help format the resulting HTML. So, there are a few things I do after the document is rendered to make sure it imports into Ulysses with a minimal amount of fuss. Here is an example showing:
- Lines with
:::indicate boundaries to<span>objects for CSS formatting. - The code blocks contain both the language (
.r) and the css (.cell-code) components.
::: {.cell}
```{.r .cell-code}
1 + 1
```
::: {.cell-output .cell-output-stdout}
```
[1] 2
```
:::
:::
None of this is necessary for what we need, so I’m going to try to figure out a solution here. This will be a bit ‘suboptimal,’ and I expect to update you on this going forward. But here is my quick fix using the Shortcuts application.
This shortcut was configured as a Quick Action item in the Finder. What this means (I just found out) is that when you select a file in a Finder window, shortcuts are provided in the bottom gutter of the display…. I never knew this was an option!
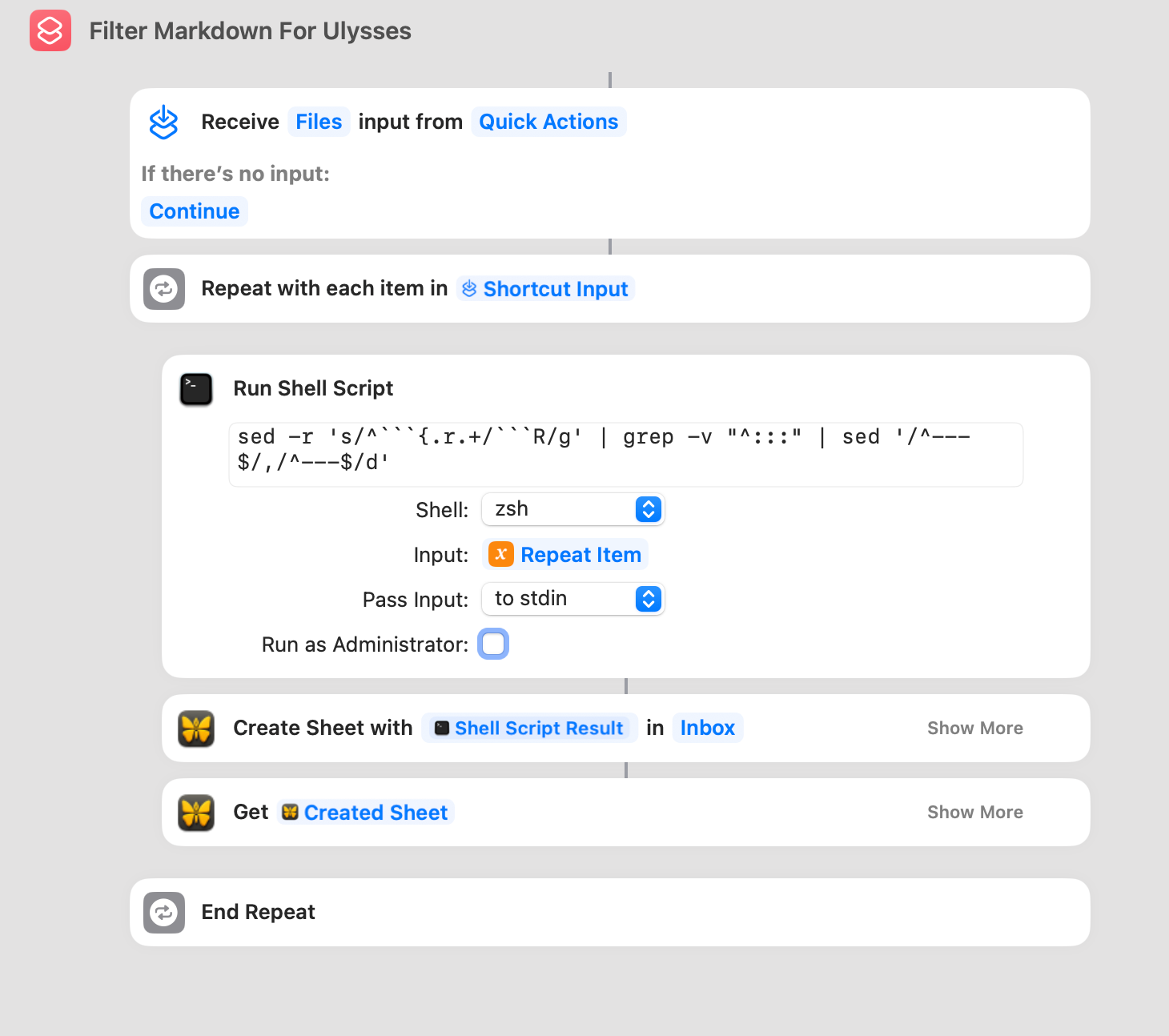
OK, so the shortcut itself is a mix of bash stuff to do the cleanup that:
- Opens each file selected.
- Read the contents
- Filters out the code boundary and triple colon lines and removes the YML header components.
- Opens Ulysses
- Create a new sheet in the
Inbox - Put that content into the new sheet.
Challenges Yet to Overcome
Well, this works just fine, though there are some limitations. This could be expanded from the Ulysses shortcut options.
There are at least three additional things that should be implemented.
- I should remove the
bashstuff and use only shortcut steps for clarity. - I should extract the
title:line and put it as the H1 element at the top of the file. - I should replace the images that Quarto makes and puts into the subfolders and insert them into the sheet. (And change the corresponding link)
I’ll have to get back to this.